vignesh yaadavFine-Tuning wav2vec2 on your Google Colab: Take a deep dive into advanced audio classification…The inspiration for embarking on this remarkable audio classification journey struck during my early morning jogs. As I ventured into the…Sep 8, 2023Sep 8, 2023
InAkvelonbyDmitrii LukianovGenerating Subtitles with OpenAI WhisperKey TakeawaysMar 15, 20232Mar 15, 20232
tttzof351Build text-to-speech from scratch.In the series of small articles, we will write step-by-step a toy text-to-speech model. It will be a simple model with a modest goal — to…Aug 2, 20231Aug 2, 20231
InLevel Up CodingbyAli5 Killer Python Libraries For Audio ProcessingData Science projects, music composition, and lots more…Nov 28, 20221Nov 28, 20221
InPython in Plain EnglishbyEverton Gomede, PhDAudio Segmentation and Artificial Intelligence: A Harmonious SymphonyIntroductionOct 4, 20231Oct 4, 20231
Inaxinc-aibyDavid CochardSileroVAD : Machine Learning Model to Detect Speech SegmentsThis is an introduction to「SileroVAD」, a machine learning model that can be used with ailia SDK. You can easily use this model to create…Dec 26, 2023Dec 26, 2023
Insho.jpbySho NakagomeFourier Transform 101 — Part 5: Fast Fourier Transform (FFT)Disclaimer! It’s not Final Fantasy Tactics! I mean I like the game, but this one is cool too.Mar 17, 20191Mar 17, 20191
InAnalytics VidhyabyDavid Castro PiñolMultichannel Speech Enhancement Using Deep Neural NetworksA brief description of current methods in the state of the art literatureFeb 25, 2022Feb 25, 2022
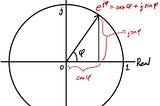
Insho.jpbySho NakagomeFourier Transform 101 — Part 1: Real Fourier SeriesIn this series, I’m going to explain about Fourier Transform. Have you heard of the term? If not, that’s totally fine. This will be the…Sep 27, 20181Sep 27, 20181
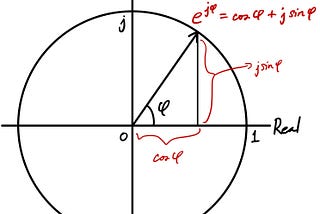
Insho.jpbySho NakagomeFourier Transform 101 — Part 2: Complex Fourier SeriesLast time, I covered Real Fourier Series based on lectures from Dr. Wim van Drongelen.Oct 2, 20181Oct 2, 20181
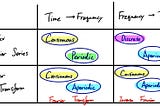
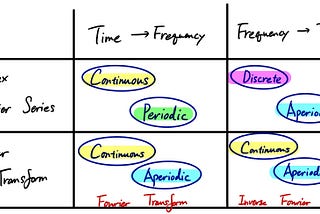
Insho.jpbySho NakagomeFourier Transform 101 — Part 3: Fourier TransformPreviously, we covered the basic ideas behind Fourier Series starting from the “Real Fourier Series”.Oct 10, 2018Oct 10, 2018
InTDS ArchivebyKung-Hsiang, Huang (Steeve)Automatic Speech Recognition Data Collection with Youtube V3 API, Mask-RCNN and Google Vision APIBackgroundAug 26, 20186Aug 26, 20186
InLinagora LABSbyRudy BARAGLIAVoice Activity Detection for Voice User Interface.As a part of a R&D team at Linagora, I have been working on several Speech based technologies involving Voice Activity Detection (VAD) for…Jun 20, 20181Jun 20, 20181
InViVoLabbyPablo Gimeno JordánViVoVAD: A Voice Activity Detection Tool Based on Recurrent Neural NetworksPablo Gimeno Jordán, @Ignacio Viñals, @Alfonso Ortega, Antonio Miguel Artiaga, Eduardo LleidaJun 4, 2019Jun 4, 2019
Antony M. GitauFrom Raw Data to Accurate Speech Recognition (ASR): My journey of Data Preparation.My journey started by visiting the Mozilla Common Voice project[1], a publicly available database of crowd-sourced voice datasets for…Feb 15, 2023Feb 15, 2023
Onkar PatilHow to Remove Silence from an Audio using PythonThere are many ways available that remove the silence part or the dead spaces from an audio file but it’s time consuming to know which one…Jun 30, 20221Jun 30, 20221
InTDS ArchivebyMax HilsdorfAI Music Source Separation: How it Works and Why It Is So HardSource Separation AI, explainedSep 21, 20233Sep 21, 20233
InTDS ArchivebyAhmed BesbesDeploy a Voice-Based Chatbot with BentoML, LangChain, and GradioBentoML is Like Lego for ML engineersMay 2, 20233May 2, 20233
InTDS ArchivebyZoumana KeitaHow to Perform Speech-to-Text and Translate Any Speech to English With OpenAI’s WhisperHow to use cutting-edge NLP models for audio transcription to text and machine translation.Dec 14, 20223Dec 14, 20223